|
§3 MemCalc解析
|
|||||||||||||||
| §§3-4 予測解析 |
|||||||||||||||
|
問 ある種の時系列データを解析する目的の一つは,将来におけるその挙動を予測することにあります。しかし、そもそも予測とは常に可能なものなのでしょうか? |
1200 | ||||||||||||||
|
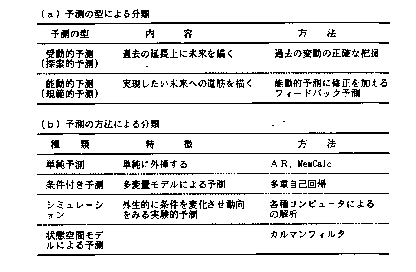
答 予測には,受動的予測と能動的予測の2通りがあります.受動的予測は,過去から現在までの推移から未来を推し計るものです.一方,能動的予測とは,受動的予測を基礎としつつも,未来における期待値をあらかじめ設定し,それに向かうように現象を推移させようとするものです.しかしながら,この能動的予測の場合,現象の客観的推移を正しく把握することが前提になるため,受動的予測の側面をいいかげんにすることは許されません.こうして,予測というのは,結局は過去から現在までの現象の推移をどれだけ正確にとらえきれるかという問題に帰着することになります.その上で,未来に起こる現象の要因は無数にあり,その全てを私たちがあらかじめ知ることは不可能ですので,予測には常に限界がつきまといます. |
|||||||||||||||
|
問 これまでの予測解析の考え方は,どのようなものですか? |
1210 | ||||||||||||||
|
答 これまでの予測解析の考え方は,過去の時系列に含まれる誤差と未来における未知部分とが存在することを理由に,確率的・統計的予測が大勢を占めてきました.しかしこれでは結局,予測を非決定論的世界に落とし込むことになってしまいます.一方,経済分野(特に,大手証券会社や銀行)で構築されている“意思決定支援システム(MSS:management support system)”における環境予測システムでは,30~50本の構造方程式,同数程度の定義式,100を優に超える内生変数と外生変数などからなる多元連立非線形方程式群を大型コンピュ-タで解いて解を求めます.これは決定論的ではありますが,非線形方程式の困難さを度外視した方法で全く意味をもちません.こうした状況の結果として予測の科学性,客観性が失われ,「予測は当たらない」とか「予測は困難である」などと言う評判が流布し,“賭け・卦・占い”の類と同一視されることになっています. |
|||||||||||||||
|
問 近年,非線形時系列の予測解析の研究が盛んに行われていますが,あまりうまくいっているように見えません.この原因は何だと思いますか? |
1220 | ||||||||||||||
|
答 カオス時系列の予測に関しては,代表的な研究の成果がA.S.WeigendとN.A.Gershenfeld編
"Time Series Prediction -Forcasting
the Future and Understanding the Past-"(1994)にまとめられています.その教科書では,カオス時系列の予測法として,自己回帰(AR)法,時間遅れの埋め込みによる状態空間の再構成そしてニュ-ラルネットワ-クなどのいくつかの注目すべき方法が紹介されています.この中でARはカオス過程には不適当です.なぜなら,AR過程に基づく線形モデルは,カオスのような非線形系を記述することは不可能であると考えられるからです.他の2つの方法は,予測の手続きをマスタ-することが簡単ではありません. |
|||||||||||||||
|
問 MemCalcでは,予測解析は可能ですか? |
1230 | ||||||||||||||
|
答 予測の基本は,過去から現在までの変動構造を調べ,それを未来に延長して未来の変動構造を推し量ることです.MemCalcを用いることによって,この基本に立ち戻り,改めて科学的・客観的な予測の方式を確立できます.表1230に,予測の種類がまとめられています.このまとめからも分かるように,予測の基本としては,何よりも先ず“過去の時系列の構造の正確な解明”が大前提になります.MemCalcは,所与の時系列の変動構造,とりわけ周期構造,を解明する点では,圧倒的に優秀な解析システムです.
|
|||||||||||||||
|
問 MemCalcでは予測解析はどのように行いますか? |
1240 | ||||||||||||||
|
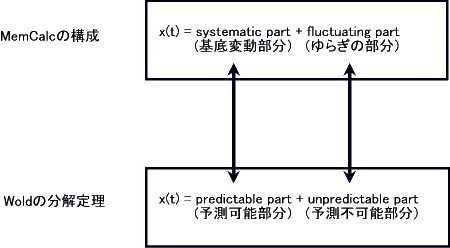
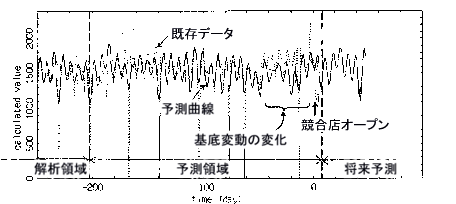
答 MemCalcでは,その比類なき卓越した“時系列変動構造の解析能力”を利用して,過去の時系列の変動構造を決定し,それを未来に延長します.過去の時系列の変動構造は,MemCalcの構成要素として導入した“基底変動”として求められます.MemCalcによって決定される“基底変動”は,ウオルドの分解定理(Wold's decomposition theorem)における“予測可能部分(predictable
part)”に数学的表現形式も含め対応しています(図1240).こうして,MemCalcによる予測は,過去の時系列の構造を完全に把握し,それを未来に延長する結果,過去の構造がどこまで持続するかの検討が可能となります.即ち,過去の状況と違った未来の新たな状況をはじめてとらえることを可能にしています.
|
|||||||||||||||
|
問 MemCalcによる予測解析が他の方法よりも優れていることを示す具体的な事例はありますか? |
1250 | ||||||||||||||
|
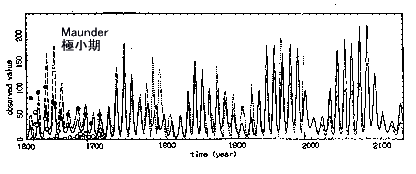
答 太陽黒点数は,多くの研究者によって時系列解析方法のテスト用のデ-タとしても用いられてきましたが,太陽黒点数の変動を説明できる解析方法はこれまで皆無であり,まして“小氷河期”に関わっている“マウンダ-極小期”も含めてとなると,全く絶望的でありました.説明できないことの理由に,太陽活動は不規則で予測不能な振舞いをする(最近ではカオス変動と言われている),あるいは太陽黒点数が
ウオルフ(Wolf)による評価方法によって算出されるため,かなりあいまいな量となっている,などが指摘されていました.
|
|||||||||||||||
|
問 これまでの経済データの予測解析はことごとく失敗しているようですが,MemCalcではどうですか? |
1260 | ||||||||||||||
|
答 MemCalcを用いた経済デ-タ変動の予測解析は,数年前から,ユ-コ-プ事業連合(神奈川生協を中心とする事業連合体)において実施されてきました.現在莫大な種類と量の時系列デ-タの解析を通して,経済データに対するMemCalcの活用の可能性の実証をほぼ終了しています.
|
|||||||||||||||
|
問 MemCalcは短い時系列の解析にも有用であるということですが,それは予測解析にも言えますか? |
1270 | ||||||||||||||
|
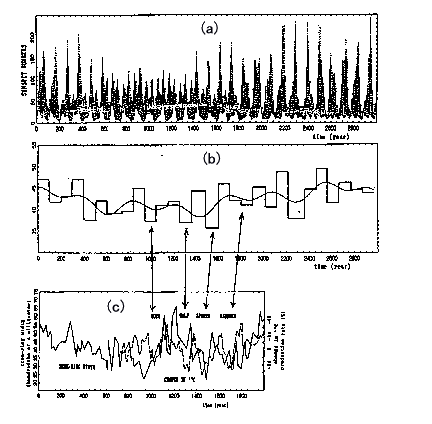
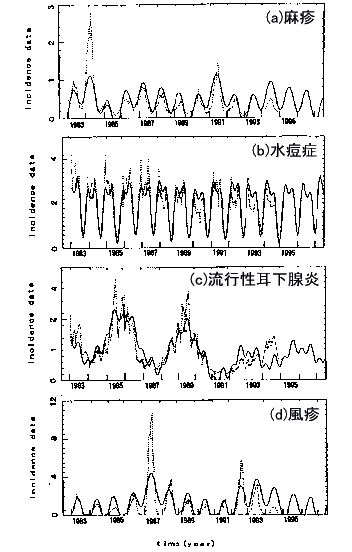
答 MemCalcによる短い時系列の予測解析の例として,感染症サーベイランスにおいて蓄積された,データ長500点の感染症発生患者数の結果があります(参考文献2-6).図1270に,(a)麻疹,(b)水痘症,(c)流行性耳下腺炎(ムンプス),(d)風疹についての結果を示します.図1270では,解析領域(1983~1992)のLSF曲線(実線)が原データ(点線)の基底変動を十分に再現していることが見て取れます.予測曲線は,このLSF曲線を解析領域(1983~1992)から予測領域(1993~1994)に延長することによって得られます.各感染症の予測解析の結果は以下のとおりです.
|
|||||||||||||||
|
問 予測の程度(正確さ)をどのような基準で評価するのですか? |
1280 | ||||||||||||||
|
答 MemCalcを用いた予測解析の主要な目的は,あてはめ度の高いLSF曲線を計算するのではなくて,原データの基底変動を構成する主要な周期モードを決定して,これらの周期モードを予測解析に用いることにあります. |